오차 줄이고 속도 2배 높여...DB분야 최우수학술대회에서 발표

한양대 인공지능학과 정우환 교수팀이 AI를 기반으로 데이터베이스 최적화 기술을 개발했다고, 한양대가 28일 밝혔다. 이번 연구에서 정 교수팀은 예측모델(Dream)과 데이터 생성알고리즘(TEDDY, SODDY), 모델학습방법(Packed Learning)을 모두 새롭게 개발함으로써 기존 대비 오차를 40% 가량 줄임과 동시에 학습속도는 2배가량 빨라진 기술을 개발했다.
데이터베이스를 효율적으로 작동시키기 위해 먼저 질의처리의 최적화 (Query optimization)가 매우 중요하다. 정 교수팀은 질의 최적화에 필수적인 질의결과크기 예측알고리즘을 딥러닝 모델을 활용해 개발했다.
그간 딥러닝 모델을 활용해 질의결과크기를 예측하기 위한 연구가 있었지만 딥러닝 모델학습에 필요한 시간, 높은 비용 등의 제약으로 인해 실제 데이터베이스에 활용하기에는 어려움이 있었다.
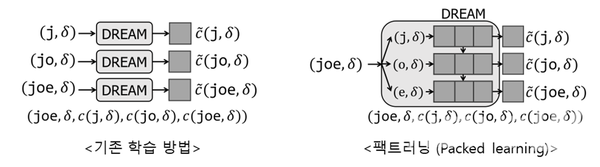
이런 문제점을 해결하고자 정 교수팀은 기존 대비 13배 이상 빠른 속도로 학습 데이터를 생성하는 알고리즘(TEDDY, SODDY)을 개발했다. 이를 이용할 경우 짧은 시간에 양질의 학습데이터를 얻을 수 있다. 이와 함께 정 교수팀이 제안한 팩트러닝(Packed Learning) 모델학습방법을 통해 학습시간을 비약적으로 감소시켰다. 이를 기반으로 같은 구조의 딥러닝 모델을 이용하더라도 오차를 20% 가량 줄임과 동시에 학습시간을 50% 이상 감소시킬 수 있었다.
정 교수는 “이번 연구는 딥러닝 기반 데이터베이스 최적화에서 대부분의 시간을 차지하는 데이터 생성 및 모델학습시간을 획기적으로 줄인데 의의가 있다”고 말했다.
서울대 심규석 교수, 서울대 권수용 연구원이 공동으로 참여했고, 과학기술정보통신부의 AI융합혁신대학원사업, 중견연구지자원사업, 정보통신방송연구개발사업의 지원을 받아 수행된 이번 연구결과는 지난 9월 호주 시드니에서 개최된 데이터베이스분야 세계최고권위 국제학술대회 VLDB 2022 (International Conference on Very Large Databases)에서 발표됐다.

 '한양위키' 키워드 보기
'한양위키' 키워드 보기