Reduce the error and double the speed...Presented at the Best Academic Conference in DB

Hanyang University announced on the 28th that a team of Professor Jung Woo-hwan of the Department of Artificial Intelligence at Hanyang University has developed a database optimization technology based on AI. In this study, Professor Jung's team developed a technology to reduce error by 40% and double the speed of learning with new predictive model (Dream), data generation algorithm (TEDDY, SODDY), and packed learning method.
In order to operate the database efficiently, Query optimization is very important. Professor Jung's team developed an algorithm of query performance prediction that is essential for query optimization by using a deep learning model.
Although there have been studies to predict the volume of query performance with deep learning, it has been difficult to use them in actual databases due to the time and high cost required for deep learning model learning.
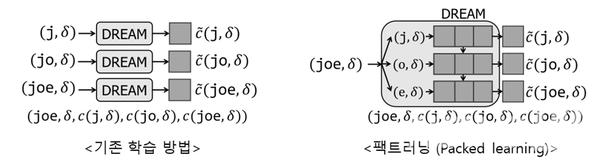
To solve this problem, Professor Jung's team developed an algorithm (TEDDY, SODY) that generates learning data more than 13 times faster than before. If one uses this, one can obtain high-quality of learning data in a short time. In addition, the learning time was drastically reduced through the Packed Learning proposed by Professor Jung's team. Even if the deep learning model with the same structure was used, the error could be reduced by 20% and the learning time could be reduced by more than 50%.
Professor Jung said, "This study is meaningful in that data generation and model learning time are drastically reduced, which takes up most of the time in deep learning-based database optimization."
This study is conducted by Professor Shim Kyu-seok of Seoul National University and researcher Kwon Soo-yong of Seoul National University, which was supported by the Ministry of Science and ICT's AI Convergence Innovation Project, Mid-sized Research Resources Project, and Information and Communication Broadcasting R&D Project. The results of this study were presented at the VLDB 2022 (International Conference on Very Large Databases) in Sydney, Australia in September.

키워드
 '한양위키' 키워드 보기
#SDG9
'한양위키' 키워드 보기
#SDG9