데이터 사이언스 분야 최우수 국제 컨퍼런스에서 발표
향후 다양한 AI 영역에서 높은 활용 가능성 보여
한양대 컴퓨터소프트웨어학부 김상욱 교수팀이 최근 대규모 딥러닝 모델학습을 위한 학습률(learning rate) 조정기술 ‘LENA’을 개발했다고, 한양대가 21일 밝혔다.
LENA는 기존 기술 대비 절반 이하의 학습 시간으로도 모델 학습을 성공적으로 완료했으며, 나아가 기존 기술이 실패했던 대규모 학습 상황에서도 모델 학습을 성공적으로 완료한 것으로 나타났다.
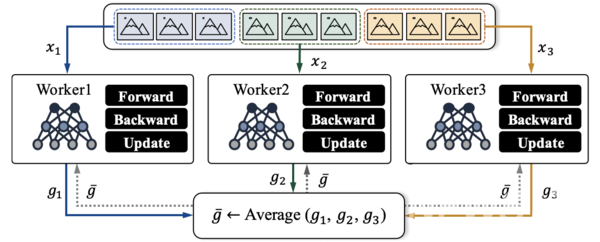
딥러닝은 수많은 계층(layer)으로 구성된 신경망 모델을 이용해 빅데이터를 학습하는 기술로, 4차 산업혁명을 위한 핵심기술로 평가받고 있다. 그러나 딥러닝은 빅데이터 학습을 위해 방대한 시간과 컴퓨팅 자원이 필요하며 이는 딥러닝 연구개발의 큰 장애물로 지적돼왔다. 이런 단점을 해소하고자 최근 학계 및 산업계에서는 딥러닝 가속화를 위한 데이터 병렬(data parallelism)에 관한 연구를 활발히 진행하고 있다.
데이터 병렬 학습에서 워커들의 학습 결과를 모델에 얼마만큼 반영할 지를 나타내는 값을 학습률이라 하며, 학습률이 높을수록 학습결과를 모델에 많이 반영한다는 것을 의미한다.
일반적으로 학습이 진행될수록, 학습의 규모(동시에 학습하는 데이터의 양)가 증가할수록, 학습 결과의 질이 높아지는 경향이 있다. 따라서 이러한 경우 양질의 학습 결과를 모델에 많이 반영하기 위해 학습률을 높게 설정한다.
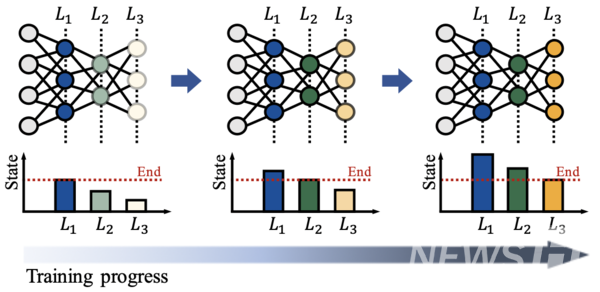
딥러닝 모델은 수많은 계층으로 구성되며, 각 계층은 자신만의 고유한 역할을 가지고 있다. 김 교수팀은 계층별 역할 차이에 대한 이해를 기반으로 ‘계층별 최적의 학습률이 다를 것’이라는 가정을 세우고 면밀한 분석을 거쳐 계층별로 학습 상태가 현저히 다르다는 것을 확인했다.
이러한 분석을 통해 김 교수팀은 기존 학습률 조정 기법들이 모델의 계층별 학습 상태의 차이를 고려하지 않고 모든 계층에 동일한 학습률을 적용하고 있음을 밝혔고, 이것이 대규모 데이터 병렬 학습 시 모델 정확도를 떨어뜨리는 원인임을 파악했다.
이를 기반으로 김 교수팀은 모델의 계층별 학습 진행 상태에 따라 학습률을 차별화해 조정하는 기술 ‘LENA’를 개발했다. LENA는 모델에 대한 학습 진행 상태를 계층별로 따로 파악하고, 이를 기반으로 각 계층에 대한 학습률을 차별화해 결정한다.
이와 더불어 대규모 데이터 병렬 학습의 초기에 발생할 수 있는 학습불안정 문제를 완화하기 위한 ‘계층별 학습률 워밍업(warm-up) 전략’도 함께 제안했다.
그 결과 LENA는 기존 학습률 조정 기법들과 비교해 약 45%의 학습 시간만으로 동일한 모델 정확도를 빠르게 달성했고, 기존 학습률 조정 기법들이 실패했던 대규모 학습 상황에서도 높은 모델 정확도를 달성했다.
LENA는 현존하는 딥러닝 기술뿐 아니라 향후 개발될 미래 기술에도 적용 가능해 AI 분야의 많은 영역에서 활용될 수 있는 잠재력이 큰 기술로 평가받는다.
이번 연구는 한국연구재단(NRF), 정보통신기획평가원(IITP)의 지원을 받아 한양대 고윤용 박사와 미국 펜실베니아 주립대 이동원 교수가 함께 진행했다.
한편 LENA은 그 기술의 독창성 및 우수성을 인정받아 오는 25일부터 닷새간 개최되는 ‘The ACM Web Conference 2022(TheWebConf2022)’에서 발표될 예정이다. TheWebConf은 세계적으로 인정받는 데이터 사이언스 분야의 최우수 컨퍼런스 중 하나다.


|
|
관련기사
- 김상욱 교수팀, 2배 빨라진 새로운 딥러닝 기술 개발
- 한국공학한림원 2021신입 회원 발표 ... 한양대 9명 이름 올려
- 김상욱 교수, 그래프 빅데이터 처리속도 대폭 향상
- NHN엔터 사외이사에 김상욱 교수 선임
- 김상욱 교수 연구실, 빅데이터 분야 'SW스타랩'으로 선정
- 김상욱 교수, NHN 그룹 ESG 전담조직 위원장으로 임명
- 김상욱 교수 연구실의 'VITA', 빠르고 정교한 처방 기술로 의료 질 개선에 힘쓰다
- 한양대 김상욱 교수팀, 리뷰 기반 개인화 추천 정확도 23% 높인 AI 기술 ‘LETTER’ 개발
- 한양대 김상욱 교수팀, AI 기반 네트워크 임베딩 기술로 KDD 2025 우수 논문상 수상
키워드
 '한양위키' 키워드 보기
#김상욱
'한양위키' 키워드 보기
#김상욱