컴퓨터 비전 및 자연어처리 모델 학습속도 1.5배~2배 향상
한양대 컴퓨터소프트웨어학부 서지원 교수팀이 최근 BERT, GPT-3 등의 대규모 딥러닝 모델 학습을 가속하는 최적화 기술을 개발했다. 해당 기술은 딥러닝 모델을 학습하는 그래픽카드(GPU) 등의 하드웨어 가속기 사용률을 높여 학습을 가속시킨다. 이를 통해 서 교수팀은 상대적으로 적은 수의 하드웨어 가속기로 대규모 모델 학습을 가능하게 만들었다.
이번 연구는 컴퓨터시스템 분야 세계최고 학술대회 ‘EuroSys(The European Conference on Computer Systems)’에 발표됐으며, 대규모 신경망 모델 학습을 가속화할 뿐 아니라 향후 다양한 방식으로 활용될 수 있다는 점에서 학계와 업계의 주목을 받고 있다.
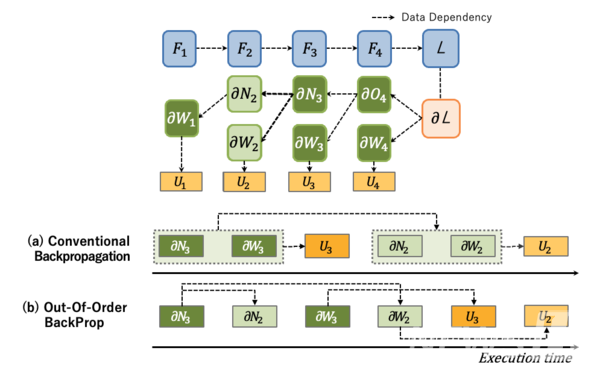
기존의 딥러닝 모델 학습방식은 역전파(BackProp) 알고리즘 수행 시 딥러닝 모델 레이어의 역순으로만 계산을 스케줄링하기 때문에 하드웨어 가속기를 효율적으로 사용할 수 있는 스케줄링이 불가능했다. 서 교수팀은 이런 단점을 개선하고자 역전파 알고리즘 과정의 계산 의존성을 분석, 하드웨어의 가용성을 최적화하는 순서로 역전파 알고리즘 계산을 하는 ‘스케줄링 알고리즘’을 고안했다.
서 교수팀은 분석 과정에서 파라미터 기울기 계산(Weight Gradient Computation)의 경우 딥러닝 모델의 레이어 역순으로 계산하지 않고 다른 순서로 스케줄링 하는 것이 가능하다는 것을 파악했고, 이를 활용해 스케줄링을 하는 ‘비순차적 역전파(Out-Of-Order BackProp)’ 기법을 개발했다.
해당 기법은 딥러닝 모델 학습 시 일반적으로 광범위하게 적용될 수 있는 기법으로, 특히 대규모 딥러닝 모델의 분산 학습에 적용해 효율적인 스케줄링 알고리즘을 만들 수 있었다.
이를 통해 서 교수팀은 분산 학습의 대표방식인 데이터 병렬학습(Data Parallel Training)과 파이프라인 병렬학습(Pipeline Parallel Training)에서 임계경로(Critical Path)에 있는 파라미터 기울기 계산의 우선순위를 높이는 스케줄링 기법을 적용해 최적화했다.
그 결과 서 교수팀이 제안한 스케줄링 알고리즘은 DenseNet, MobileNet 등을 포함한 컴퓨터 비전 모델의 학습속도를 최대 1.5배 이상 향상시고, BERT·GPT-3 등의 거대 자연어처리 모델의 학습 속도를 최대 2배 향상시켰다.
서 교수의 연구 결과는 EuroSys 학술대회 발표 후 우수성을 인정받아 영국 임페리얼 칼리지 런던, 미국 스탠포드 대학에서 초청발표가 진행됐다. 또 산업계의 주목도 받아 미국 구글 본사, 네이버 클로바, LG AI연구원, KT, SKT, 몰로코, 마키나락스 등의 초청을 받고 세미나가 열렸다.
정보통신기획평가원(IITP)과 주식회사 KT의 지원을 받은 이번 연구는 오형준, 이준열, 김형주 한양대 석·박사과정 학생들과 함께 진행됐다. 한편 서지원 교수는 KT AI원팀에 참여해 이번 연구에서 개발된 기술을 적용하는 연구를 진행하고 있다.
 '한양위키' 키워드 보기
'한양위키' 키워드 보기